This is a two part post, you can see part 1 here. Please read that post (if you haven't already) before continuing or just check out the code in this gist.
from **future** import division
import string
import math
tokenize = lambda doc: doc.lower().split(" ")
document*0 = "China has a strong economy that is growing at a rapid pace. However politically it differs greatly from the US Economy."
document*1 = "At last, China seems serious about confronting an endemic problem: domestic violence and corruption."
document*2 = "Japan's prime minister, Shinzo Abe, is working towards healing the economic turmoil in his own country for his view on the future of his people."
document*3 = "Vladimir Putin is working hard to fix the economy in Russia as the Ruble has tumbled."
document*4 = "What's the future of Abenomics? We asked Shinzo Abe for his views"
document*5 = "Obama has eased sanctions on Cuba while accelerating those against the Russian Economy, even as the Ruble's value falls almost daily."
document_6 = "Vladimir Putin is riding a horse while hunting deer. Vladimir Putin always seems so serious about things - even riding horses. Is he crazy?"
all*documents = [document*0, document*1, document*2, document*3, document*4, document*5, document*6]
def jaccard_similarity(query, document):
intersection = set(query).intersection(set(document))
union = set(query).union(set(document))
return len(intersection)/len(union)
def term*frequency(term, tokenized*document):
return tokenized_document.count(term)
def sublinear*term*frequency(term, tokenized*document):
count = tokenized*document.count(term)
if count == 0:
return 0
return 1 + math.log(count)
def augmented*term*frequency(term, tokenized*document):
max*count = max([term*frequency(t, tokenized*document) for t in tokenized*document])
return (0.5 + ((0.5 \* term*frequency(term, tokenized*document))/max*count))
def inverse*document*frequencies(tokenized*documents):
idf*values = {}
all*tokens*set = set([item for sublist in tokenized*documents for item in sublist])
for tkn in all*tokens*set:
contains*token = map(lambda doc: tkn in doc, tokenized*documents)
idf*values[tkn] = 1 + math.log(len(tokenized*documents)/(sum(contains*token)))
return idf_values
def tfidf(documents):
tokenized*documents = [tokenize(d) for d in documents]
idf = inverse*document*frequencies(tokenized*documents)
tfidf*documents = []
for document in tokenized*documents:
doc*tfidf = []
for term in idf.keys():
tf = sublinear*term*frequency(term, document)
doc*tfidf.append(tf \* idf[term])
tfidf*documents.append(doc*tfidf)
return tfidf_documents
in Scikit-Learn
from sklearn.feature_extraction.text import TfidfVectorizer
sklearn*tfidf = TfidfVectorizer(norm='l2',min*df=0, use*idf=True, smooth*idf=False, sublinear*tf=True, tokenizer=tokenize)
sklearn*representation = sklearn*tfidf.fit*transform(all_documents)
Cosine Similarity
Now that we've covered TF-IDF and how to do with our own code as well as Scikit-Learn. Let's take a look at how we can actually compare different documents with cosine similarity or the Euclidean dot product formula.
At this point our documents are represented as vectors.
print tfidf_representation[0]
print sklearn_representation.toarray()[0].tolist()
This will show you what they actually are.
With cosine similarity we can measure the similarity between two document vectors. I'm not going to delve into the mathematical details about how this works but basically we turn each document into a line going from point X to point Y. We then compare that directionality with the second document into a line going from point V to point W. We measure how large the cosine angle is in between those representations.
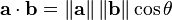
We can rearrange the above formula to a more implementable representation like that below.
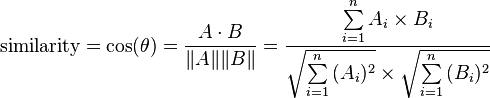
Now in our case, if the cosine similarity is 1, they are the same document. If it is 0, the documents share nothing. This is because term frequency cannot be negative so the angle between the two vectors cannot be greater than 90°.
Here's our python representation of cosine similarity of two vectors in python.
def cosine_similarity(vector1, vector2):
dot_product = sum(p\*q for p,q in zip(vector1, vector2))
magnitude = math.sqrt(sum([val\*\*2 for val in vector1])) \* math.sqrt(sum([val\*\*2 for val in vector2]))
if not magnitude:
return 0
return dot_product/magnitude
Now that we have a vector representation and a way to compare different vectors we can put it to good use. But before we do, we should add that the final benefit of cosine similarity is now all our documents are off the same length, this removes any bias we had towards longer documents (like with Jaccard Similarity).
tfidf_representation = tfidf(all_documents)
our_tfidf_comparisons = []
for count_0, doc_0 in enumerate(tfidf_representation):
for count_1, doc_1 in enumerate(tfidf_representation):
our_tfidf_comparisons.append((cosine_similarity(doc_0, doc_1), count_0, count_1))
skl_tfidf_comparisons = []
for count_0, doc_0 in enumerate(sklearn_representation.toarray()):
for count_1, doc_1 in enumerate(sklearn_representation.toarray()):
skl_tfidf_comparisons.append((cosine_similarity(doc_0, doc_1), count_0, count_1))
for x in zip(sorted(our_tfidf_comparisons, reverse = True), sorted(skl_tfidf_comparisons, reverse = True)):
print x
# ((1.0000000000000002, 4, 4), (1.0000000000000002, 6, 6))
# ((1.0000000000000002, 3, 3), (1.0000000000000002, 5, 5))
# ...
# ((0.2931092569884059, 4, 2), (0.29310925698840595, 4, 2))
# ((0.2931092569884059, 2, 4), (0.29310925698840595, 2, 4))
# ((0.16506306906464613, 6, 3), (0.16506306906464616, 6, 3))
# ...
# ((0.0, 1, 4), (0.0, 1, 4))
# ((0.0, 1, 3), (0.0, 1, 3))
# ((0.0, 1, 2), (0.0, 1, 2))
# ignore the .00000...2, it's just float representations in python being off of what they should be
What is interesting here is that we're getting the exact same similarities from our representation as well as Scikit-Learn's. This is because we're doing apples to apples comparisons (they are creating the vectors through the same way). We say that even though the TFIDF matrices generated by our different algorithms were different. It doesn't change anything down the road because vectors are just numerical representations of our sentences.
Now you've learned a lot so far. We've created some vectors to better understand document vector representations, we've compared them and seen how we can leverage that representation to take a look at similarity. With a little tweaking you could even create a simple search engine that would search documents for certain terms.
Now there are plenty of places for improvement, better tokenization and stemming could really help to improve our algorithms but that's for another post.
Here is all the code I used for this post series.
from **future** import division
import string
import math
tokenize = lambda doc: doc.lower().split(" ")
document*0 = "China has a strong economy that is growing at a rapid pace. However politically it differs greatly from the US Economy."
document*1 = "At last, China seems serious about confronting an endemic problem: domestic violence and corruption."
document*2 = "Japan's prime minister, Shinzo Abe, is working towards healing the economic turmoil in his own country for his view on the future of his people."
document*3 = "Vladimir Putin is working hard to fix the economy in Russia as the Ruble has tumbled."
document*4 = "What's the future of Abenomics? We asked Shinzo Abe for his views"
document*5 = "Obama has eased sanctions on Cuba while accelerating those against the Russian Economy, even as the Ruble's value falls almost daily."
document_6 = "Vladimir Putin is riding a horse while hunting deer. Vladimir Putin always seems so serious about things - even riding horses. Is he crazy?"
all*documents = [document*0, document*1, document*2, document*3, document*4, document*5, document*6]
def jaccard_similarity(query, document):
intersection = set(query).intersection(set(document))
union = set(query).union(set(document))
return len(intersection)/len(union)
def term*frequency(term, tokenized*document):
return tokenized_document.count(term)
def sublinear*term*frequency(term, tokenized*document):
count = tokenized*document.count(term)
if count == 0:
return 0
return 1 + math.log(count)
def augmented*term*frequency(term, tokenized*document):
max*count = max([term*frequency(t, tokenized*document) for t in tokenized*document])
return (0.5 + ((0.5 \* term*frequency(term, tokenized*document))/max*count))
def inverse*document*frequencies(tokenized*documents):
idf*values = {}
all*tokens*set = set([item for sublist in tokenized*documents for item in sublist])
for tkn in all*tokens*set:
contains*token = map(lambda doc: tkn in doc, tokenized*documents)
idf*values[tkn] = 1 + math.log(len(tokenized*documents)/(sum(contains*token)))
return idf_values
def tfidf(documents):
tokenized*documents = [tokenize(d) for d in documents]
idf = inverse*document*frequencies(tokenized*documents)
tfidf*documents = []
for document in tokenized*documents:
doc*tfidf = []
for term in idf.keys():
tf = sublinear*term*frequency(term, document)
doc*tfidf.append(tf \* idf[term])
tfidf*documents.append(doc*tfidf)
return tfidf_documents
in Scikit-Learn
from sklearn.feature_extraction.text import TfidfVectorizer
sklearn*tfidf = TfidfVectorizer(norm='l2',min*df=0, use*idf=True, smooth*idf=False, sublinear*tf=True, tokenizer=tokenize)
sklearn*representation = sklearn*tfidf.fit*transform(all_documents)
###### ##### END BLOG POST 1
def cosine*similarity(vector1, vector2):
dot*product = sum(p*q for p,q in zip(vector1, vector2))
magnitude = math.sqrt(sum([val**2 for val in vector1])) \* math.sqrt(sum([val*\*2 for val in vector2]))
if not magnitude:
return 0
return dot_product/magnitude
tfidf*representation = tfidf(all*documents)
our*tfidf*comparisons = []
for count*0, doc*0 in enumerate(tfidf*representation):
for count*1, doc*1 in enumerate(tfidf*representation):
our*tfidf*comparisons.append((cosine*similarity(doc*0, doc*1), count*0, count_1))
skl*tfidf*comparisons = []
for count*0, doc*0 in enumerate(sklearn*representation.toarray()):
for count*1, doc*1 in enumerate(sklearn*representation.toarray()):
skl*tfidf*comparisons.append((cosine*similarity(doc*0, doc*1), count*0, count_1))
for x in zip(sorted(our*tfidf*comparisons, reverse = True), sorted(skl*tfidf*comparisons, reverse = True)):
print x
For further reference: