Chat with Your Data using LangChain
Note: See the accompanying GitHub repo for this blogpost here.
ChatGPT has taken the world by storm. But while it’s great for general purpose knowledge, it only knows information about what it has been trained on, which is pre-2021 generally available internet data. It doesn’t know about your private data nor does it know recent sources of data.
Wouldn’t it be useful if it did?
This blog post is a tutorial on how to set up your own version of ChatGPT over a specific corpus of data. There is an accompanying GitHub repo that has the relevant code referenced in this post. Specifically, this deals with text data. For how to interact with other sources of data with a natural language layer, see the below tutorials:
High Level Overview
At a high level, there are two components to setting up ChatGPT over your own data: (1) ingestion of the data, (2) chatbot over the data. Let's talk a bit about the steps involved in each of those.
Ingestion of data
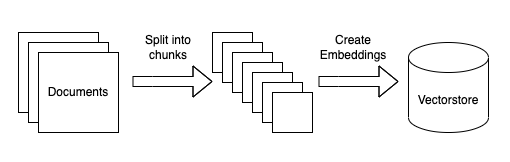
Ingestion involves several steps. The steps are:
- Load data sources to text: this involves loading your data from arbitrary sources to text in a form that it can be used downstream. This is one place where we hope the community will help out!
- Chunk text: this involves chunking the loaded text into smaller chunks. This is necessary because language models generally have a limit to the amount of text (tokens) they can deal with. "Chunk size" is something to be tuned over time.
- Embed text: this involves creating a numerical embedding for each chunk of text. This is necessary because we only want to select the most relevant chunks of text for a given question, and we will do this by finding the most similar chunks in the embedding space.
- Load embeddings to vectorstore: this involves putting embeddings and documents into a vectorstore. Vectorstores help us find the most similar chunks in the embedding space quickly and efficiently.
Langchain strives to be modular, so that each of these steps are straightforward to swap out with other components or approaches.
Querying of Data
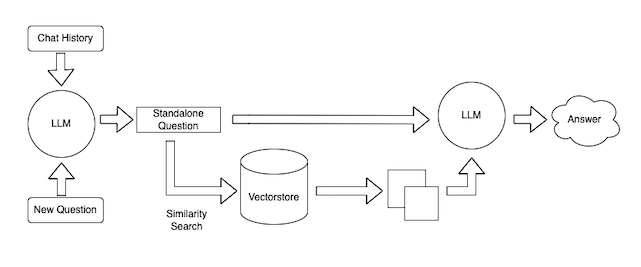
This can also be broken down into a few steps. The high level steps are:
- Get input from the user: we'll use a web interface and a cli interface to receive input from the user about the documents.
- Combine that input with chat history: we'll combine chat history and a new question into a single standalone question. This is often necessary because we want to allow for the ability to ask follow up questions (an important UX consideration).
- Lookup relevant documents: using the vectorstore created during ingestion, we will look up relevant documents for the answer.
- Generate a response: Given the standalone question and the relevant documents, we will use a language model to generate a response.
In this post, we'll explore some design decisions you have with history, prompts, and the chat experience. We won't touch on the deployment, but for more information see our deployment guide.
Step by Step Details
This section dives into more detail on the steps necessary to ingest data.
Load data
First, we need to load data into a standard format. In langchain, a Document consists of (1) the text itself, (2) any metadata associated with that text (where it came from, etc). This is often critical for understanding and communicating the context for testing or for the end user.
The community has contributed dozens of document loaders and we look forward to seeing more and more join the community. See our documention (and over 120 data loaders) for more information about document loaders. Please open a pull request or file an issue if you'd like to contribute (or request) a new document loader.
The line below contains the line of code responsible for loading the relevant documents.
print("Loading data...")
loader = UnstructuredFileLoader("state_of_the_union.txt")
raw_documents = loader.load()
Split Text
Splitting documents into smaller units of text for input into the model is critical for getting relevant information back from our chatbot. When documents are too big, you'll include irrelevant information to the model. Conversely, when they're too small, you'll not include enough information and the model may be confused about what is actually relevant.
The chunk size isn't quite a science, so you'll have to experiment to see if you can get good results.
print("Splitting text...")
text_splitter = CharacterTextSplitter(
separator="\n\n",
chunk_size=600,
chunk_overlap=100,
length_function=len,
)
documents = text_splitter.split_documents(raw_documents)
Create embeddings and store in vectorstore
Next, now that we have small chunks of text we need to create embeddings for each piece of text and store them in a vectorstore. We create embeddings because this is an efficient way of storing this text data and subsequently querying the store for documents relevant to our query.
Here we use OpenAI’s embeddings and a FAISS vectorstore and store that as a python pickle file for later use.
print("Creating vectorstore...")
embeddings = OpenAIEmbeddings()
vectorstore = FAISS.from_documents(documents, embeddings)
with open("vectorstore.pkl", "wb") as f:
pickle.dump(vectorstore, f)
Run python ingest_data.py to create the vectorstore. This is necessary after changing how you split the text or loading new documents. If you're making changes, adding documents, or splitting text different, you'll have to re-run things.
Query data
So now that we’ve ingested the data, we can now use it in a chatbot interface. In order to do this, we will use the ConversationalRetrievalChain.
There are several different options when it comes to querying the data. Do you allow follow up questions? Want to include other user context? There are lots of design decisions and below we'll discuss some of the most critical.
Do you want to have conversation history?
This is table stakes from a UX perspective because it allows for follow up questions. Adding memory is simple, you can either use a built in module.
llm = ChatOpenAI(model_name="gpt-4", temperature=0)
retriever = load_retriever()
memory = ConversationBufferMemory(
memory_key="chat_history", return_messages=True)
# model = RetrievalQA.from_llm(llm=llm, retriever=retriever)
# if you don't want memory use the above, you will have to change
# the app.py or cli_app.py file to include `query` in the input instead of `question`
model = ConversationalRetrievalChain.from_llm(
llm=llm,
retriever=retriever,
memory=memory)
Alternatively, you can specify memory and pass it into the model, tracking it on your own. Run this example from the github repo with the following, then read the code in query_data.py.
python cli_app.py
Which QA model would you like to work with? [basic/with_sources/custom_prompt/condense_prompt] (basic):
Chat with your docs!
---------------
Your Question: (what did the president say about ketanji brown?):
Answer: The President nominated Ketanji Brown Jackson to serve on the United States Supreme Court, describing her as one of the nation's top legal minds who will continue Justice Breyer's legacy of excellence. He also mentioned that she
is a former top litigator in private practice, a former federal public defender, and comes from a family of public school educators and police officers. He referred to her as a consensus builder and noted that since her nomination, she
has received a broad range of support from various groups, including the Fraternal Order of Police and former judges appointed by both Democrats and Republicans.
---------------
Do you want to customize the QA prompt?
You can easily customize the QA prompt by passing in a prompt of your choice. This is similar in experience to most all chains in langchain. Learn more about custom prompts here.
template = """You are an AI assistant for answering questions about the most recent state of the union address.
You are given the following extracted parts of a long document and a question. Provide a conversational answer.
If you don't know the answer, just say "Hmm, I'm not sure." Don't try to make up an answer.
If the question is not about the most recent state of the union, politely inform them that you are tuned to only answer questions about the most recent state of the union.
Lastly, answer the question as if you were a pirate from the south seas and are just coming back from a pirate expedition where you found a treasure chest full of gold doubloons.
Question: {question}
=========
{context}
=========
Answer in Markdown:"""
QA_PROMPT = PromptTemplate(template=template, input_variables=[
"question", "context"])
llm = ChatOpenAI(model_name="gpt-4", temperature=0)
retriever = load_retriever()
memory = ConversationBufferMemory(
memory_key="chat_history", return_messages=True)
model = ConversationalRetrievalChain.from_llm(
llm=llm,
retriever=retriever,
memory=memory,
combine_docs_chain_kwargs={"prompt": QA_PROMPT})
Run this example from the github repo with the following, then read the code in query_data.py.
python cli_app.py
Which QA model would you like to work with? [basic/with_sources/custom_prompt/condense_prompt] (basic): custom_prompt
Chat with your docs!
---------------
Your Question: (what did the president say about ketanji brown?):
Answer: Arr matey, the cap'n, I mean the President, he did speak of Ketanji Brown Jackson, he did. He nominated her to the United States Supreme Court, he did, just 4 days before his address. He spoke highly of her, he did, callin' her
one of the nation's top legal minds. He believes she'll continue Justice Breyer’s legacy of excellence, he does.
She's been a top litigator in private practice, a federal public defender, and comes from a family of public school educators and police officers. She's a consensus builder, she is. Since her nomination, she's received support from all
over, from the Fraternal Order of Police to former judges appointed by both Democrats and Republicans. So, that's what the President had to say about Ketanji Brown Jackson, it is.
---------------
Your Question: (what did the president say about ketanji brown?): who did she succeed?
Answer: Arr matey, ye be askin' about who Judge Ketanji Brown Jackson be succeedin'. From the words of the President himself, she be takin' over from Justice Breyer, continuin' his legacy of excellence on the United States Supreme
Court. Now, let's get back to countin' me gold doubloons, aye?
---------------
Do you expect long conversations?
If so, you're going to want to condense previous questions and history in order to add context into the prompt. If you embed the whole chat history along with the new question to look up relevant documents, you may pull in documents no longer relevant to the conversation (if the new question is not related at all). Therefor, this step of condensing the chat history and a new question to a standalone question is very important.
_template = """Given the following conversation and a follow up question, rephrase the follow up question to be a standalone question.
You can assume the question about the most recent state of the union address.
Chat History:
{chat_history}
Follow Up Input: {question}
Standalone question:"""
CONDENSE_QUESTION_PROMPT = PromptTemplate.from_template(_template)
llm = ChatOpenAI(model_name="gpt-4", temperature=0)
retriever = load_retriever()
memory = ConversationBufferMemory(
memory_key="chat_history", return_messages=True)
# see: https://github.com/langchain-ai/langchain/issues/5890
model = ConversationalRetrievalChain.from_llm(
llm=llm,
retriever=retriever,
memory=memory,
condense_question_prompt=CONDENSE_QUESTION_PROMPT,
combine_docs_chain_kwargs={"prompt": QA_PROMPT}) # includes the custom prompt as well
Read the code in query_data.py for some example code to apply to your own projects.
Do you want the model to cite sources?
Langchain can cite source documents in the model.. There's a lot you can do here, you can add your own metadata, your own sections, and other relevant information to return the most relevant metadata for your query.
llm = ChatOpenAI(model_name="gpt-4", temperature=0)
retriever = load_retriever()
history = []
model = ConversationalRetrievalChain.from_llm(
llm=llm,
retriever=retriever,
return_source_documents=True)
def model_func(question):
# bug: this doesn't work with the built-in memory
# see: https://github.com/langchain-ai/langchain/issues/5630
new_input = {"question": question['question'], "chat_history": history}
result = model(new_input)
history.append((question['question'], result['answer']))
return result
model_func({"question":"some question you have"})
# this is the same interface as all the other models.
Run this example from the github repo with the following, then read the code in query_data.py.
python cli_app.py
Which QA model would you like to work with? [basic/with_sources/custom_prompt/condense_prompt] (basic): with_sources
Chat with your docs!
---------------
Your Question: (what did the president say about ketanji brown?):
Answer: The President nominated Ketanji Brown Jackson to serve on the United States Supreme Court, describing her as one of the nation's top legal minds who will continue Justice Breyer's legacy of excellence. He also mentioned that she
is a former top litigator in private practice, a former federal public defender, and comes from a family of public school educators and police officers. Since her nomination, she has received a broad range of support, including from the
Fraternal Order of Police and former judges appointed by both Democrats and Republicans.
Sources:
state_of_the_union.txt
One of the most serious constitutional responsibilities a President has is nominating someone to serve on the United States Supreme Court.
And I did that 4 days ago, when I nominated Circuit Court of Appeals Judge Ketanji Brown Jackson. One of our nation’s top legal minds, who will continue Justice Breyer’s legacy of excellence.
state_of_the_union.txt
As I said last year, especially to our younger transgender Americans, I will always have your back as your President, so you can be yourself and reach your God-given potential.
While it often appears that we never agree, that isn’t true. I signed 80 bipartisan bills into law last year. From preventing government shutdowns to protecting Asian-Americans from still-too-common hate crimes to reforming military
justice.
state_of_the_union.txt
But in my administration, the watchdogs have been welcomed back.
We’re going after the criminals who stole billions in relief money meant for small businesses and millions of Americans.
And tonight, I’m announcing that the Justice Department will name a chief prosecutor for pandemic fraud.
By the end of this year, the deficit will be down to less than half what it was before I took office.
The only president ever to cut the deficit by more than one trillion dollars in a single year.
Lowering your costs also means demanding more competition.
state_of_the_union.txt
A former top litigator in private practice. A former federal public defender. And from a family of public school educators and police officers. A consensus builder. Since she’s been nominated, she’s received a broad range of
support—from the Fraternal Order of Police to former judges appointed by Democrats and Republicans.
And if we are to advance liberty and justice, we need to secure the Border and fix the immigration system.
We can do both. At our border, we’ve installed new technology like cutting-edge scanners to better detect drug smuggling.
---------------
Your Question: (what did the president say about ketanji brown?): where did she work before?
Answer: Before her nomination to the United States Supreme Court, Ketanji Brown Jackson worked as a Circuit Court of Appeals Judge. She was also a former top litigator in private practice and a former federal public defender.
Sources:
state_of_the_union.txt
One of the most serious constitutional responsibilities a President has is nominating someone to serve on the United States Supreme Court.
And I did that 4 days ago, when I nominated Circuit Court of Appeals Judge Ketanji Brown Jackson. One of our nation’s top legal minds, who will continue Justice Breyer’s legacy of excellence.
state_of_the_union.txt
A former top litigator in private practice. A former federal public defender. And from a family of public school educators and police officers. A consensus builder. Since she’s been nominated, she’s received a broad range of
support—from the Fraternal Order of Police to former judges appointed by Democrats and Republicans.
And if we are to advance liberty and justice, we need to secure the Border and fix the immigration system.
We can do both. At our border, we’ve installed new technology like cutting-edge scanners to better detect drug smuggling.
state_of_the_union.txt
We cannot let this happen.
Tonight. I call on the Senate to: Pass the Freedom to Vote Act. Pass the John Lewis Voting Rights Act. And while you’re at it, pass the Disclose Act so Americans can know who is funding our elections.
Tonight, I’d like to honor someone who has dedicated his life to serve this country: Justice Stephen Breyer—an Army veteran, Constitutional scholar, and retiring Justice of the United States Supreme Court. Justice Breyer, thank you for
your service.
state_of_the_union.txt
Vice President Harris and I ran for office with a new economic vision for America.
Invest in America. Educate Americans. Grow the workforce. Build the economy from the bottom up and the middle out, not from the top down.
Because we know that when the middle class grows, the poor have a ladder up and the wealthy do very well.
America used to have the best roads, bridges, and airports on Earth.
Now our infrastructure is ranked 13th in the world.
We won’t be able to compete for the jobs of the 21st Century if we don’t fix that.
---------------
Language Model
The final lever to pull is what language model you use to power your chatbot. In our example we use the OpenAI LLM, but this can easily be substituted to other language models that LangChain supports, or you can even write your own wrapper.
Putting it all together
After making all the necessary customizations, and running python ingest_data.py, you can now interact with the chatbot.
We’ve exposed a really simple interface through which you can do. You can access this just by running python cli_app.py and this will open in the terminal a way to ask questions and get back answers. Try it out!
We also have an example of deploying this app via Gradio! You can do so by running python app.py. This can also easily be deployed to Hugging Face spaces - see example space here.
